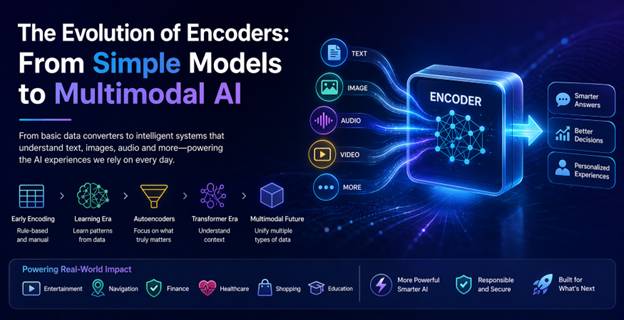
Quand on parle d’intelligence artificielle, on pense d’abord à ses résultats : textes qui sonnent juste, images spectaculaires ou recommandations ciblées. Mais avant tout cela, l’IA doit “comprendre” les données qu’on lui fournit. Ce travail commence par les encodeurs, des composants qui transforment des informations du monde réel en représentations structurées exploitables par les modèles.
Au fil des progrès, ces encodeurs ont évolué : d’simples convertisseurs de données, ils sont devenus des systèmes capables de traiter le sens et de gérer plusieurs types d’informations à la fois. Une progression progressive, façonnée par des besoins concrets et des défis techniques.
De la conversion de données à l’apprentissage
Au début de l’apprentissage automatique, l’encodage relevait surtout de la mise en forme. Les développeurs devaient définir manuellement comment représenter les données : par exemple, associer des catégories comme “petit”, “moyen” ou “grand” à des valeurs numériques. Le système pouvait alors traiter ces nombres, mais il ne “comprenait” pas réellement les relations entre les concepts : il exécutait des règles à partir de la représentation fournie.
La dynamique change avec l’arrivée des réseaux neuronaux. L’idée devient moins de prescrire des transformations et davantage de laisser le modèle apprendre des régularités directement à partir des données. En reconnaissance d’images, par exemple, l’encodeur repère progressivement des motifs (formes, textures, structures) à partir d’images annotées. En langage, les mots ne sont plus de simples symboles : ils sont convertis en vecteurs qui capturent des relations sémantiques, permettant par exemple de rapprocher des expressions proches même si elles ne sont pas formulées de la même manière.
Les autoencodeurs : comprimer pour reconstruire
Une étape importante de cette évolution passe par les autoencodeurs. Leur principe est simple : comprimer des données tout en préservant l’essentiel, puis tenter de les reconstruire à partir de cette version réduite. Pour y parvenir, l’encodeur apprend quels éléments sont déterminants et lesquels peuvent être ignorés.
Ce mécanisme a trouvé des usages pratiques. Dans la détection de fraude bancaire, le modèle apprend le comportement “habituel” ; un écart significatif déclenche une alerte. Dans le stockage d’images, l’encodeur aide à réduire la taille des fichiers en conservant les informations utiles, ce qui améliore la vitesse de chargement sans dégrader excessivement la qualité perçue.
L’ère des transformeurs : le contexte comme levier
Le tournant le plus visible de l’évolution des encodeurs vient avec les modèles de type transformer. Leur force réside dans la capacité à prendre en compte le contexte de manière beaucoup plus globale. Plutôt que d’analyser un élément à la fois, ils examinent les informations dans leur ensemble et priorisent ce qui est le plus pertinent.
En langage, cette approche aide à résoudre certaines ambiguïtés. Prenez la phrase “Elle a vu l’homme avec le télescope” : qui possède l’instrument ? Les modèles fondés sur les transformeurs analysent la phrase dans sa globalité pour proposer une interprétation plus cohérente.
Cette évolution alimente une grande partie des usages du quotidien : chatbots, dictée, traduction en ligne. Le rôle de l’encodeur est alors d’arbitrer et de représenter l’information de façon suffisamment fine pour que l’interaction paraisse naturelle.
Encodage dans les services du quotidien
Même lorsque cela reste invisible, les encodeurs structurent l’expérience numérique. Les plateformes de streaming exploitent des représentations de préférences pour mieux anticiper les contenus susceptibles d’intéresser un utilisateur, en observant des régularités au fil du temps. Les applications de navigation s’appuient aussi sur des représentations de données (trafic, conditions de route, habitudes) pour suggérer des itinéraires plus rapides, parfois avant que la congestion soit pleinement perceptible.
Dans le domaine médical, les encodeurs peuvent aider à analyser des images : ils ne remplacent pas l’évaluation clinique, mais peuvent mettre en évidence des zones à examiner avec davantage d’attention.
Vers le multimodal : traiter texte, image et davantage
La dernière grande évolution concerne les encodeurs multimodaux. Au lieu de travailler uniquement sur un type de donnée, ils peuvent intégrer plusieurs modalités, par exemple le texte et l’image, dans un même traitement. L’objectif est de rapprocher davantage le fonctionnement des systèmes de la façon dont les humains appréhendent le monde.
Sur mobile, une interface pourrait analyser une photo d’une plante et répondre à une question sur son entretien en combinant ce qu’elle “voit” et ce que l’utilisateur “demande”. Dans le commerce en ligne, l’utilisateur peut parfois envoyer une image d’un produit ; le système associe alors les similarités visuelles à une compréhension plus contextuelle, pour proposer des alternatives pertinentes.
Selon l’objectif, ces encodeurs s’appuient aussi sur des outils de représentation et de déploiement optimisés, par exemple via des bibliothèques d’apprentissage et des environnements de calcul conçus pour la performance. Pour des besoins matériels, un SSD NVMe de capacité adaptée peut aider à accélérer certains traitements et chargements de données dans des pipelines d’expérimentation. Dans un autre registre, disposer d’un modèle de webcam 1080p fiable peut aussi faciliter des scénarios de prototypage multimodal impliquant de l’image en temps réel.
Des limites à prendre en compte
Cette montée en puissance s’accompagne toutefois de contraintes. Les modèles avancés demandent davantage de calcul, ce qui implique des coûts et une consommation énergétique significatifs. La question de la durabilité devient alors un sujet de conception.
La fiabilité pose aussi problème : comme les encodeurs apprennent à partir de données, ils peuvent reproduire des biais existants. Si les données d’entraînement reflètent des inégalités, les représentations apprises peuvent favoriser certains groupes au détriment d’autres. La correction exige une sélection rigoureuse des données et un suivi continu.
Enfin, la protection des données demeure un enjeu majeur. L’encodage peut impliquer le traitement d’informations personnelles ; la conformité et la sécurité doivent donc être intégrées dès la conception des systèmes.
Ce qui pourrait venir ensuite
Les prochaines avancées semblent surtout viser l’amélioration incrémentale : rendre les encodeurs plus rapides, plus efficients et moins coûteux à entraîner ou exécuter. Cela favoriserait l’accès à des capacités d’IA plus large, y compris pour des structures plus modestes.
La personnalisation est également appelée à progresser. À terme, des encodeurs pourraient mieux adapter les réponses en temps réel à des préférences ou à des styles de compréhension individuels, notamment en éducation. Et du côté multimodal, l’intégration pourrait devenir plus fluide, afin que les interfaces paraissent davantage “conversationnelles” et moins artificielles.
Au fond, l’évolution des encodeurs ressemble à une révolution discrète : elle ne se voit pas toujours à l’écran, mais elle conditionne largement ce que l’IA peut faire à partir du moment où elle reçoit de l’information brute. En transformant ces données en représentations plus riches, les encodeurs rendent l’intelligence artificielle plus utile, plus flexible et progressivement plus proche des usages humains.